



One of the most frequent concerns that we encounter when speaking with prospective customers is the safety of our agent, based on the open-source osquery project. IT teams especially worry that the agent will crash business-critical systems. In this blog post, I will explain the unique steps that Uptycs has taken to ensure that our agents do not disrupt your business and have proven successful across large enterprise environments. If you want to skip ahead and see the table of enhancements, click here.
Osquery has incredible upside potential for securing enterprise assets with its rich telemetry and scalability; however, many IT Operations and Application teams still have concerns about resource consumption of the agents. These concerns are valid, and under certain default configurations the osquery agent may consume a high amount of resources to capture and transport the large volumes of telemetry.
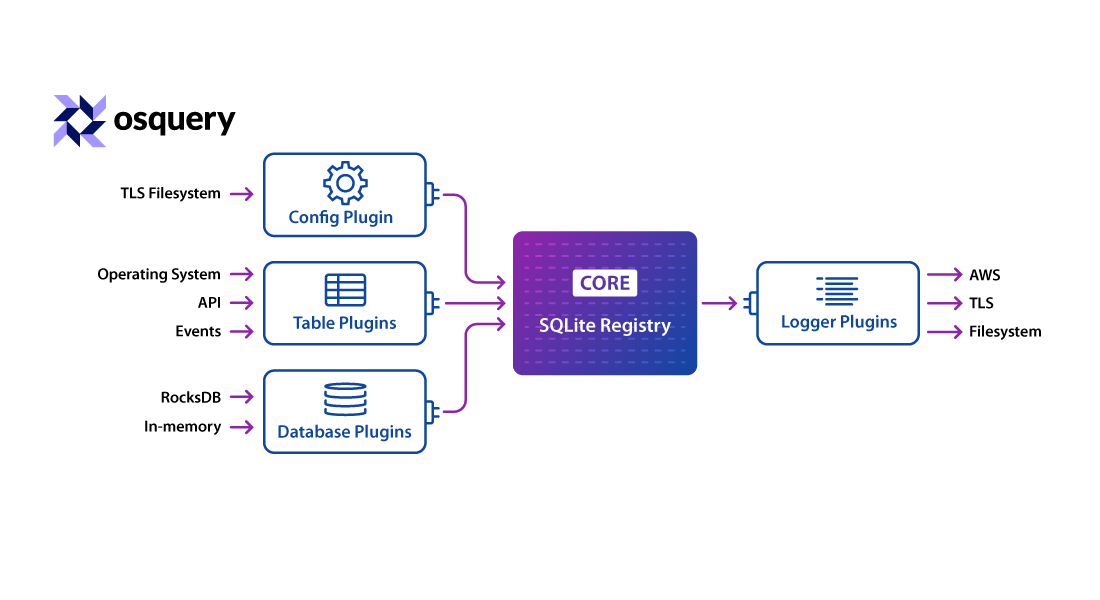
Osquery is a lightweight endpoint agent that makes your entire system configuration and runtime state available for query through an SQL interface, including a real-time stream of events.
With tailored configurations for your environment and recent optimizations from Uptycs, these concerns are addressed even when scaled up to hundreds of thousands of endpoints.
Utilized to full potential, the Uptycs agent can actually end up reducing total resource consumption on assets, as a growing number of enterprise clients realize that the telemetry captured by a single lightweight osquery agent can replace multiple other agents.
Reliable Osquery Deployment for the Paranoid
In his talk at osquery@scale 2021, Reliable osquery deployment for the paranoid, Rob Heaton at Stripe mapped out the pain points, both technological and social, associated with Stripe’s rollout of osquery to their Linux server fleet. After an initial deployment to all of Stripe’s macOS laptops, Heaton faced questions about laptops being overburdened, losing battery life, or having fans constantly running.
When pushing for additional rollout to Stripe’s server fleet, Heaton and the security team at Stripe acknowledged concerns raised around reliability and quelled fears through a layered approach consisting of three key features.
- First, the osquery watchdog acts as a direct oversight for monitoring the workers' resource consumption. Simply put, the watchdog monitors the worker for the amount of resources being used to complete each query. If a particular query exceeds a threshold level of resources over a defined period of time, then the watchdog kills the process and denylists that query for the next 24 hours. If a query is killed and denylisted, this action is logged for further analysis.
- Second, the cgroups feature in linux gives administrators the ability to monitor and limit resource consumption for specific processes. A feature similar to the watchdog, yet this is a “hard, OS-level constraint that will catch you if your watchdog ever falls asleep or you misconfigure it,” according to Heaton. Leveraging the cgroups feature (similar to Job Objects in Windows) gives a redundancy to your configuration, further mitigating any possibility of an agent creating an impact on mission critical production processes.
- Third, Heaton recommends creating a secure engineering environment that takes best practices seriously. Prior to a full rollout, it’s advised to perform an initial proof of concept in lower environments for performance testing. Stress test your system, mock-run any deployments, and push the boundaries for the day to day use cases. Additionally, it’s useful to create deployment documents, rollback procedures, and runbooks to prepare for standard use cases. Ultimately, a gradual rollout with best practices gives room for tailoring configurations and optimizing at scale for specific environments. Heaton and his team at Stripe eliminated fears around osquery’s potential for any production level issues, and are successfully leveraging the rich telemetry from osquery on every mission critical server and laptop.
Tinkering Under the Hood
Uptycs have upgraded osquery to optimize and streamline resource utilization, specifically targeting enhancements that are beneficial at large data volumes (e.g. high throughput servers or containerized workloads). Uptycs research team pushed the optimizations of osquery further and supports the key tenet that monitoring agents should never cause disruption to production workloads. We continue to support the osquery community, pushing one of the notable upgrades below to the open source project.
The majority of resource consumption issues are caused by high volumes of socket or process event data. The Uptycs osquery agent can sharply reduce resource consumption via the capability to disable the local RocksDB datastore for these events, whereby event data is sent directly to the Uptycs SaaS backend via lightweight HTTP call. This action to bypass the local RocksDB datastore significantly lowers resource consumption when querying high-volume event data, such as socket or process events.
Building on this optimization, the Uptycs team has worked continuously to research and implement enhancements that improve the underlying resource usage. The below table highlights key features presented by Founder and VP of Engineering Uma Reddy and Chief Architect Seshu Pasam at osquery@scale 2020.
|
Featured Upgrade |
Optimization Benefit |
|
Event exclusion profiles to reduce noise |
The development of event exclusion profiles gives administrators the tools to block out noise and focus on what matters.
Take for example an enterprise administrator monitoring a server cluster that has a high-volume of both intranet and internet traffic. In this scenario, the system admin is only concerned about external internet traffic. The admin leverages the event exclusion profiles feature to exclude 10.0.0.0 intranet traffic from being processed and reduce the agent's resource usage, focusing instead on analyzing external internet traffic that the admin is concerned about. |
|
Watchdog improvements to address memory allocation |
The osquery watchdog has been enhanced with monitoring capabilities that address the diversity of assets that enterprise clients deploy. Using a universal fixed amount of memory allocation for osquery is not suitable when comparing a 2 GB to 32 GB host. We developed a taxi cab algorithm to incrementally adjust the agent memory allocation as available resources scales.
This algorithm optimizes memory consumption based on resource factors such as the machine's RAM size, allowing the agent to adapt across diverse enterprise environments and ensure optimized resource consumption. So whether a device has 2 GB or 2 TB of RAM, the agent will be optimized to use a minimal percentage of resources. |
|
File integrity monitoring at scale |
We improved file integrity monitoring at scale through the introduction of exclude paths. This feature allows administrators to monitor folder paths while excluding deeper directories within those folder paths that are not within the desired scope. The exclude paths feature reduces wasted resources and optimizes file integrity monitoring. |
|
Reuse of HTTP connections for scaling |
The adoption of HTTP/1.1 brings stability and scalability to your configuration. It is burdensome to create new secure connections for every request from agent to TLS backend. Previously at scale, sockets could enter a TCP CLOSED_WAIT state on the server side or place a high churn rate on load balancers, limiting scalability under HTTP/1.0.
There are now three persistent connections to the backend: 1) Enrolling the endpoint 2) Configuration plugin 3) Distributed read query. The new distributed read query checks with the backend every 16 seconds to check if there are any real time queries to run, this reduces a lot of churn on the endpoint side and cloud backend side. The research team at Uptycs has performed an extensive amount of testing in this area and is excited for the continued improvements to this area of osquery.
The significance of this upgrade is incredibly valuable, and we contributed this upgrade back to the open source osquery community. |
|
Automatic-upgrade for osquery agents |
Leverage the auto-upgrade function to update all the osquery agents in your fleet, a major enhancement for handling hundreds of thousands of endpoints. Additionally, for enterprise managers who prefer to manually handle upgrades, there is additional support through tagging hosts into groups for targeting specific subsets or performing rolling upgrades. |
|
Heartbeat monitoring between watchdog and agent |
A “heartbeat” solution is now implemented for resolving deadlock between the watchdog and the worker. Heartbeat monitoring provides resialincy for the watchdog, stepping in when the watchdog incorrectly thinks the worker is healthy. If a deadlock is observed between the two, the worker is restarted by the heartbeat solution. The heartbeat sits between the watchdog and the worker, ensuring telemetry is produced as expected and creating an added layer of reliability. |
|
Enterprise HTTP proxy support |
Large enterprises are more likely to implement proxies across their environment, making it challenging to auto-discover for a variety of operating systems. Uptycs supports seamless connection via a proxy and remembers the last successful path to reduce connection time taken.
This is a solution that works across the different operating systems (Linux, macOS, Windows) and diverse deployments of >100,000+ endpoints. |
|
Production-grade capture of system events |
As a scheduled query sampling system, there is a concern that an event is not captured during the sampling intervals. To resolve this gap, the audit dispatch mechanism is used to send a copy of events to the osquery agent, negating the fear of missing out on any telemetry.
Audit dispatcher support captures system call activity from the ‘auditd’ mechanism. Previously, there was no mechanism to capture data from socket events or process events. We have developed capabilities that take the system calls and push them through audit controls, therefore capturing every event when the system call is run. At scale, this becomes incredibly powerful. In a matter of minutes, administrators can evaluate all possible system calls, provide rules required for your organization's audit control, and push that rule out to over 100,000+ endpoints that are seamlessly updated to the new configuration. The Uptycs platform is able to collect, process, and detect alerts much faster than traditional approaches to batch processing audit events through audit logs. We implemented resiliency to ensure the agent keeps capturing telemetry. Issues observed on the agent side are resolved through an auto-recover functionality, pushing the agent to never stall when performing event processing. |
|
Legacy operating system support |
Legacy systems are often the most vulnerable assets. Uptycs has put considerable effort into implementing legacy system support for osquery. This is incredibly beneficial as osquery used to struggle at installation or to run properly on legacy systems.
At scale, legacy OS support hardens enterprise environments, which are more likely to have legacy systems running mission critical processes. |
|
Switched to eBPF for data collection linux systems |
Historically, osquery has relied on Audit and iNotify to detect events happening on your system. Both of these frameworks have limited visibility into containers making monitoring containerized workloads nearly impossible. Leveraging eBPF allows us to run a handful of tiny high performance applications inside the Linux kernel which allows visibility into everything the kernel knows about your containers. This allows us to collect events with rich context about the container, image, process hierarchy, and other key metadata to allow for effective detection of threats on your system.
We use eBPF for data collection because it provides a significantly safer way to run code in the kernel than kernel modules. eBPF programs are validated with static analysis at load time by the kernel and run inside a special VM within the kernel. They are extremely limited to ensure performance and stability. Despite these limitations, we have been able to move much of the event exclusion logic into kernel space so that we spend very few CPU cycles collecting data for events that we know are not of interest for detection purposes. |
|
Reducing memory consumption with tcmalloc |
tcmalloc is an alternative memory allocator to what is provided by glibc. It provides high performance memory management for multi-threaded applications while minimizing internal and external fragmentation that would cause osquery to slowly increase it’s memory usage over long periods.
In addition, when running on very small VM instances, such as the AWS t2.micro with less than 1 GB of memory, we enable aggressive memory decommitting, so that osquery proactively returns unused pages to the kernel reducing the memory pressure inside your VMs. |
These enhancements make osquery an increasingly resilient solution, especially at scale. To learn more about these recent optimizations and other upgrades like REHL5 Support and Windows Table Parity, watch the full presentation from osquery@scale 2020 below.
Want to learn more about how Uptycs can help you protect your organization?
Sign Up For A Demo Today!




