

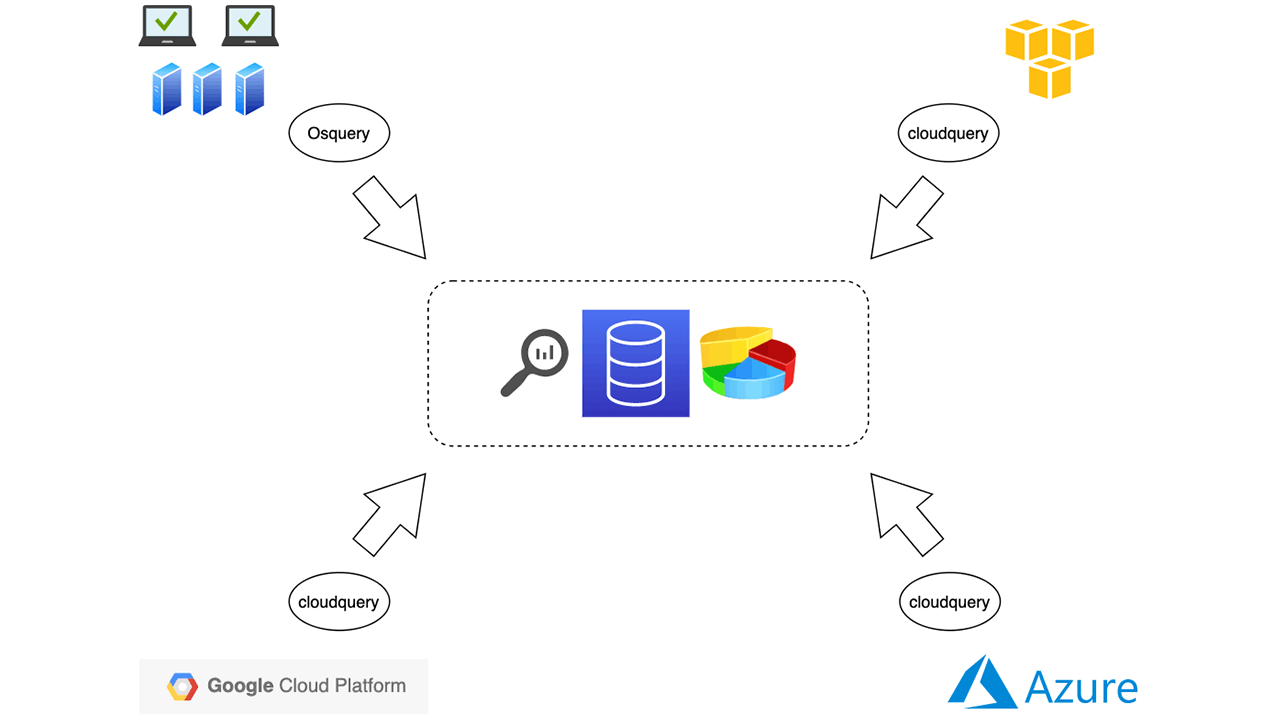
With the shift toward cloud computing, many organizations have at least some footprint in the cloud. Thus it becomes important to secure both your on-prem and CNAPP infrastructure.
Cloudquery, which runs as an extension of osquery, simplifies the visualization and monitoring of all your cloud resources. It creates a seamless integration of cloud telemetry with the rest of your osquery-powered telemetry.
All cloud providers offer ways to secure your infrastructure, but under the shared responsibility model it’s the responsibility of you, the customer, to configure and set policies to secure your cloud resources and data. With hybrid environments, it’s a challenge even to visualize resources and understand their usage. You have to deal with different tools for on-prem environments and for cloud environments.
Cloudquery uses a familiar SQL interface. This removes the need to deploy and understand various cloud provider tools. Those who are already familiar with osquery can create scheduled queries to fetch the data related to their cloud deployments and send it to configured destinations.
Apart from this, osquery’s distributed query functionality can be used to query data in real time for ad-hoc analysis. Once you collect the data and store it in a database, there are numerous ways to apply the data:
- Visualizations for various resources and their configurations
- Trends/historical data analysis and identification of configuration drift
- Detecting misconfigurations, such as S3 public buckets, and enablement of MFA for all users
- Conformance to compliance standards like CIS Benchmarks for AWS, Azure, and GCP
- Real-time investigation and root cause analysis
- Overall security
For example, the following query will provide a list of all AWS EC2 instances across all configured AWS accounts. Note that there are numerous other parameters/columns providing the details related to each instance, but this sample query (and response) shows only a few for brevity.
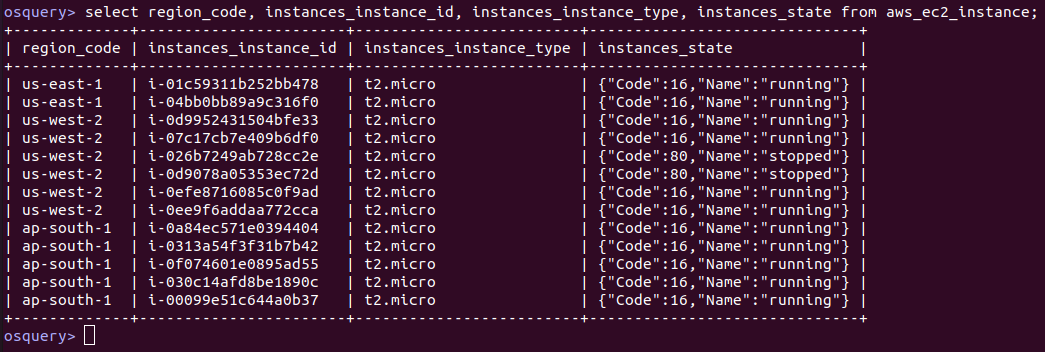
Figure 1. Query and response showing a list of AWS EC2 instances. (Click to see larger version.)
Here’s a sample query that produces a list of public S3 buckets:
SELECT account_id, name FROM aws_s3_bucket where policy_status NOT LIKE '%"IsPublic":false%';And finally, here’s a query that generates a list of instances with public IP addresses:
select account_id, region_code, instances_instance_id, instances_public_ip_address from aws_ec2_instance where instances_public_ip_address is not null AND instances_public_ip_address <> 'null';Supported Tables in Cloudquery
Cloudquery supports various cloud providers and we will keep adding new tables frequently. The list of supported tables can be found here.
Cloudquery Deployment
Cloudquery can be deployed as an osquery extension and as a Docker container. It can be deployed on-prem or in the cloud and can be configured to fetch data from one or more cloud providers. In a typical deployment you’ll have one instance of cloudquery in each cloud provider account. This makes data transfer faster and cheaper as the incoming data will not leave the perimeter of cloud deployment.
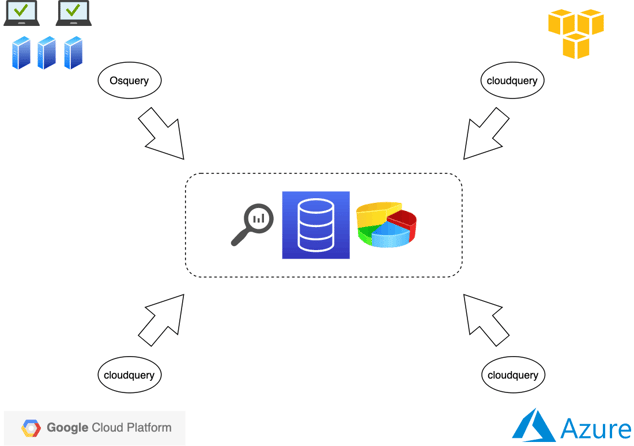
Figure 2. A typical cloudquery deployment.
Osquery vs Cloudquery
Cloudquery is an extension of osquery, not a replacement. You should install osquery on each endpoint to collect endpoint data and deploy cloudquery in each of your cloud environments to collect cloud data.
Configuring Table Schema
By default, we don’t flatten the JSON objects as it may result in an explosion of data and can incur heavy data transfer and storage costs. If required, the schema can be changed through configuration, though we strongly suggest that the flattening should be done close to the destination instead of at the source (in cloudquery).
These are the steps to change the schema of any table:
- Change respective table_config.json file
- Change the column list in respective Go code file
- Recompile the code
Let's look at an example using the aws_ec2_egress_only_internet_gateway table. By default, this table has the following schema (aws/ec2/table_config.json):
"aws_ec2_egress_only_internet_gateway": {
"aws": {
"regionCodeAttribute": "region_code",
"accountIdAttribute": "account_id"
},
"gcp": {},
"azure": {},
"parsedAttributes": [
{
"sourceName": "EgressOnlyInternetGateways_Attachments",
"targetName": "attachments",
"targetType": "TEXT",
"enabled": true
},
{
"sourceName": "EgressOnlyInternetGateways_Attachments_State",
"targetName": "attachments_state",
"targetType": "TEXT",
"enabled": false
},
{
"sourceName": "EgressOnlyInternetGateways_Attachments_VpcId",
"targetName": "attachments_vpc_id",
"targetType": "TEXT",
"enabled": false
},
{
"sourceName": "EgressOnlyInternetGateways_EgressOnlyInternetGatewayId",
"targetName": "egress_only_internet_gateway_id",
"targetType": "TEXT",
"enabled": true
},
{
"sourceName": "EgressOnlyInternetGateways_Tags",
"targetName": "tags",
"targetType": "TEXT",
"enabled": true
},
{
"sourceName": "EgressOnlyInternetGateways_Tags_Key",
"targetName": "tags_key",
"targetType": "TEXT",
"enabled": false
},
{
"sourceName": "EgressOnlyInternetGateways_Tags_Value",
"targetName": "tags_value",
"targetType": "TEXT",
"enabled": false
}
]
}With this configuration, the attachments column will be a JSON object including attachments_state and attachments_vpc_id. To have attachments_state and attachments_vpc_id as independent columns, we need to set the value of “enabled” for both of these columns to “true.”
The next step is to uncomment the attachments, attachments_state, and attachments_vpc_id column names in the code file (aws/ec2/aws_ec2_egress_only_internet_gateway.go):
// DescribeEgressOnlyInternetGatewaysColumns returns the list of columns in the table
func DescribeEgressOnlyInternetGatewaysColumns() []table.ColumnDefinition {
return []table.ColumnDefinition{
table.TextColumn("account_id"),
table.TextColumn("region_code"),
// table.TextColumn("attachments"),
table.TextColumn("attachments_state"),
table.TextColumn("attachments_vpc_id"),
table.TextColumn("egress_only_internet_gateway_id"),
table.TextColumn("tags"),
//table.TextColumn("tags_key"),
//table.TextColumn("tags_value"),
}
}After making these changes, you can rebuild the code and restart the extension with a new binary.
The Future of Cloudquery
There are lots of exciting features coming for cloudquery. PRs are welcome and appreciated. The following are some of the things planned (in no particular order):
- New inventory tables for AWS, GCP, Azure
- New tables for events (like AWS CloudTrail, AWS VPC Flow Logs)
- Support for
whereclause
More to Come
In the following video, Uma Reddy shares Uptycs’ vision for extending the capabilities of osquery to include cloud provider, container orchestrator, and SaaS provider data. These capabilities will let osquery offer inside-out and outside-in monitoring for hosts and containers.



